
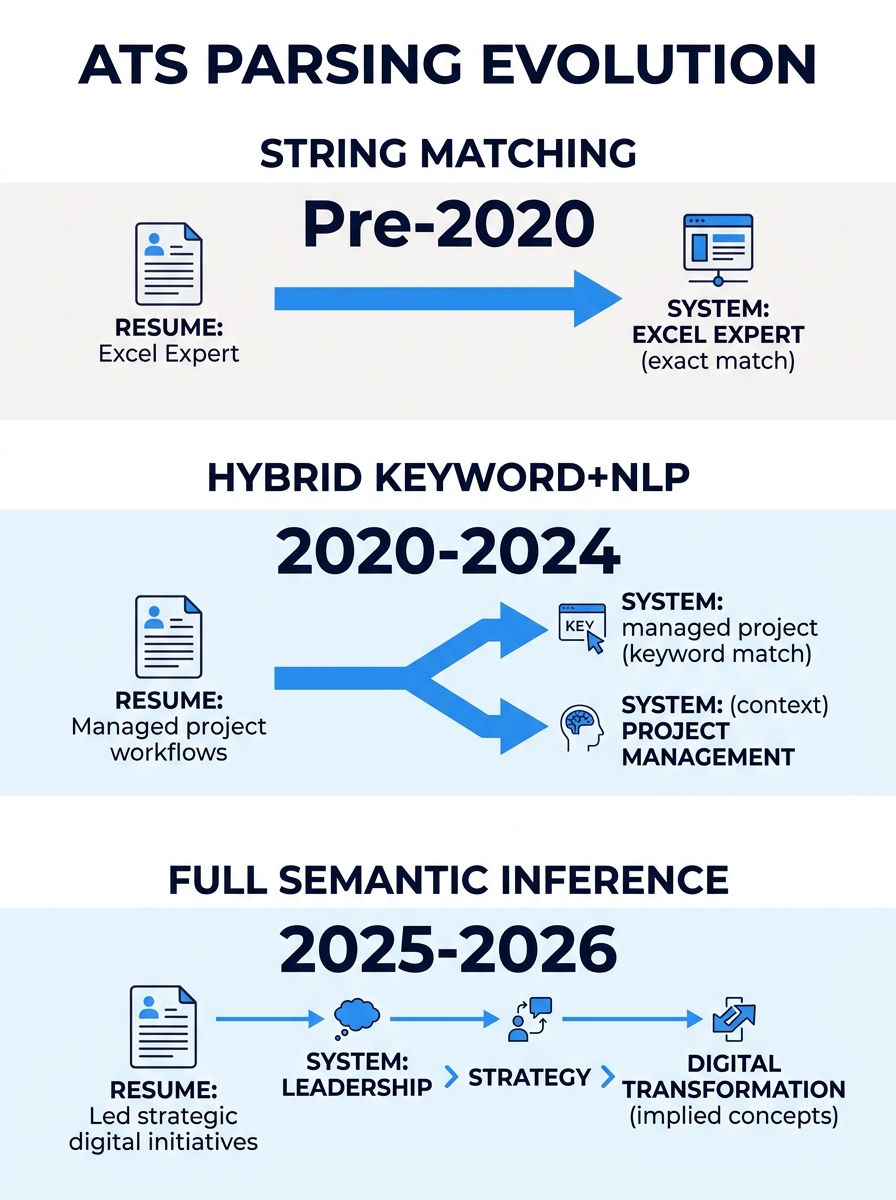
NLP-powered applicant tracking systems at over 97% of large employers now parse resumes by meaning, recognizing that “React.js” and “React” refer to the same skill and inferring capability from context rather than counting exact keyword matches. That shift from string matching to semantic inference demands a different writing strategy, one where every bullet point serves two readers simultaneously: an algorithm scoring relevance and a recruiter scanning for proof.
TL;DR: Modern ATS platforms use semantic analysis, not exact keyword matching, to score resumes. The winning approach in 2026 is “semantic mirroring”—weaving 15-25 relevant keywords into contextual, results-driven bullet points that satisfy both the parser and the hiring manager who reads what the parser surfaces.
How ATS Scoring Shifted from Keywords to Context
Prior generations of ATS software ran basic string matching: if the job posting said “project management,” the system looked for that exact phrase in your resume. Variations like “managed projects” or “program management” could slip through undetected. Advancements in NLP, particularly models derived from BERT and Word2Vec, changed the architecture. Current systems extract key resume attributes, analyze job relevance, and infer contextual qualifications dynamically, meaning a resume that discusses “led cross-functional product launches” can still score well for a posting that asks for “project management experience.”
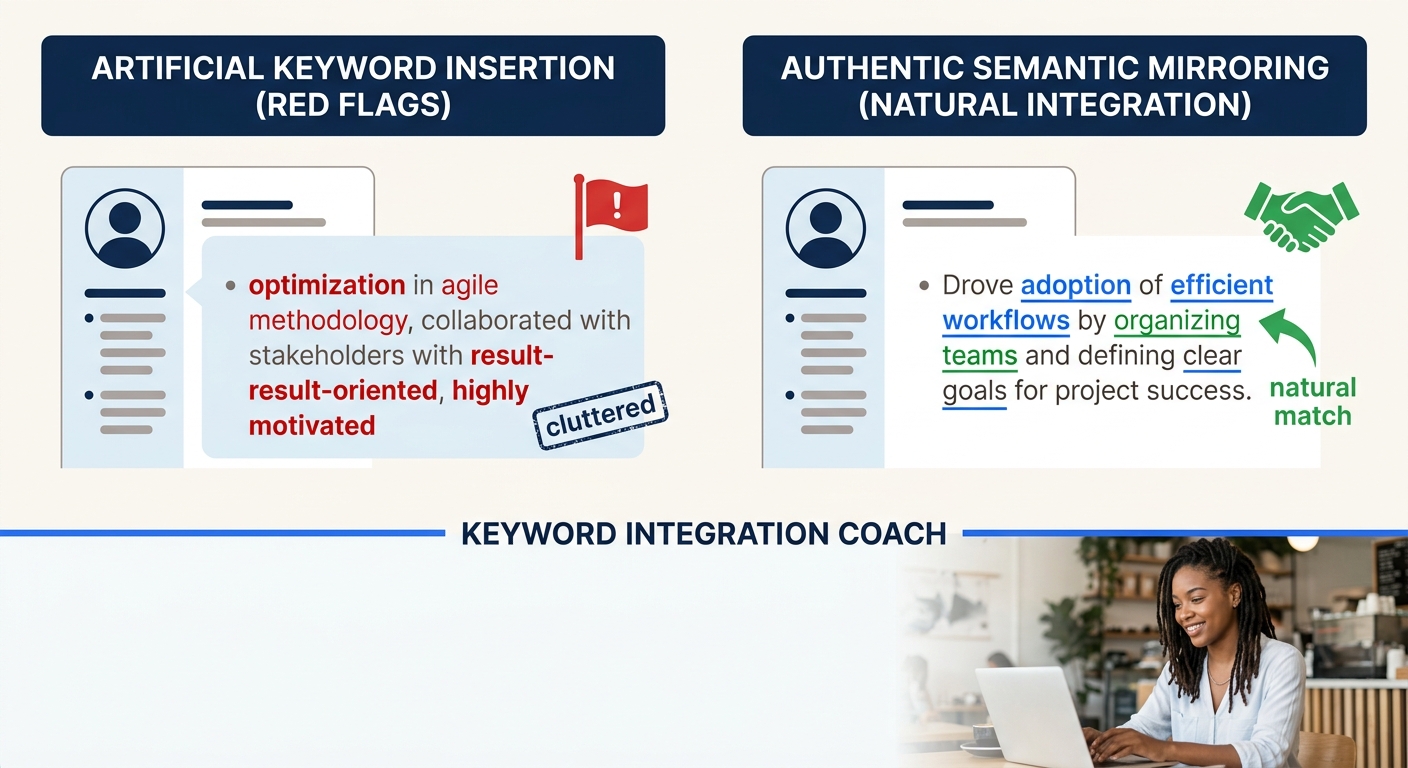
This matters because the old ATS keyword optimization playbook—where you’d repeat the exact job description phrases as often as possible—now triggers spam detection filters. According to HR Shelf’s 2026 guide, the current approach is called Semantic Mirroring, a technique that ensures the AI parser recognizes your expertise without flagging the resume as low-quality stuffing.
An 88% share of employers report losing qualified candidates because those candidates’ resumes lack ATS-friendly formatting and keyword integration, according to a survey posted on Reddit’s r/jobsearchhacks community. The irony is thick: the system designed to find good candidates actively filters them out when resumes are written for humans alone. And yet, writing exclusively for the algorithm produces a document that no recruiter wants to read.
Semantic Mirroring in Practice
Semantic mirroring means using the language ecosystem of a job posting without copying it verbatim. If a job description asks for “stakeholder communication,” your resume should include that phrase alongside related terms like “executive briefings,” “cross-departmental presentations,” or “client reporting.” The ATS maps relationships between these terms and scores your resume higher for demonstrating breadth within that skill cluster, while a recruiter reading the same bullet sees specific, credible detail.
Here’s what this looks like in a before/after comparison for a marketing manager role:
Before (keyword-stuffed): “Responsible for digital marketing, digital marketing campaigns, digital marketing strategy, and digital marketing analytics.”
After (semantic mirroring): “Designed and executed paid acquisition campaigns across Google Ads and Meta, increasing qualified lead volume 34% quarter-over-quarter while reducing cost-per-acquisition from $86 to $51.”
The second version hits “digital marketing” semantically through “paid acquisition,” “Google Ads,” “Meta,” “lead volume,” and “cost-per-acquisition.” An NLP parser connects all of these to the digital marketing skill cluster. The recruiter, meanwhile, sees quantified results and specific platforms, which is exactly what makes screening decisions happen in the first 30 seconds.
Tip: When you [reverse-engineer a job description into a targeted resume](/blog/reverse-engineer-job-description-resume), identify 8-10 critical skills from the posting and map each one to 2-3 semantically related terms you can naturally integrate into your bullet points. This creates the contextual density that modern parsers reward.
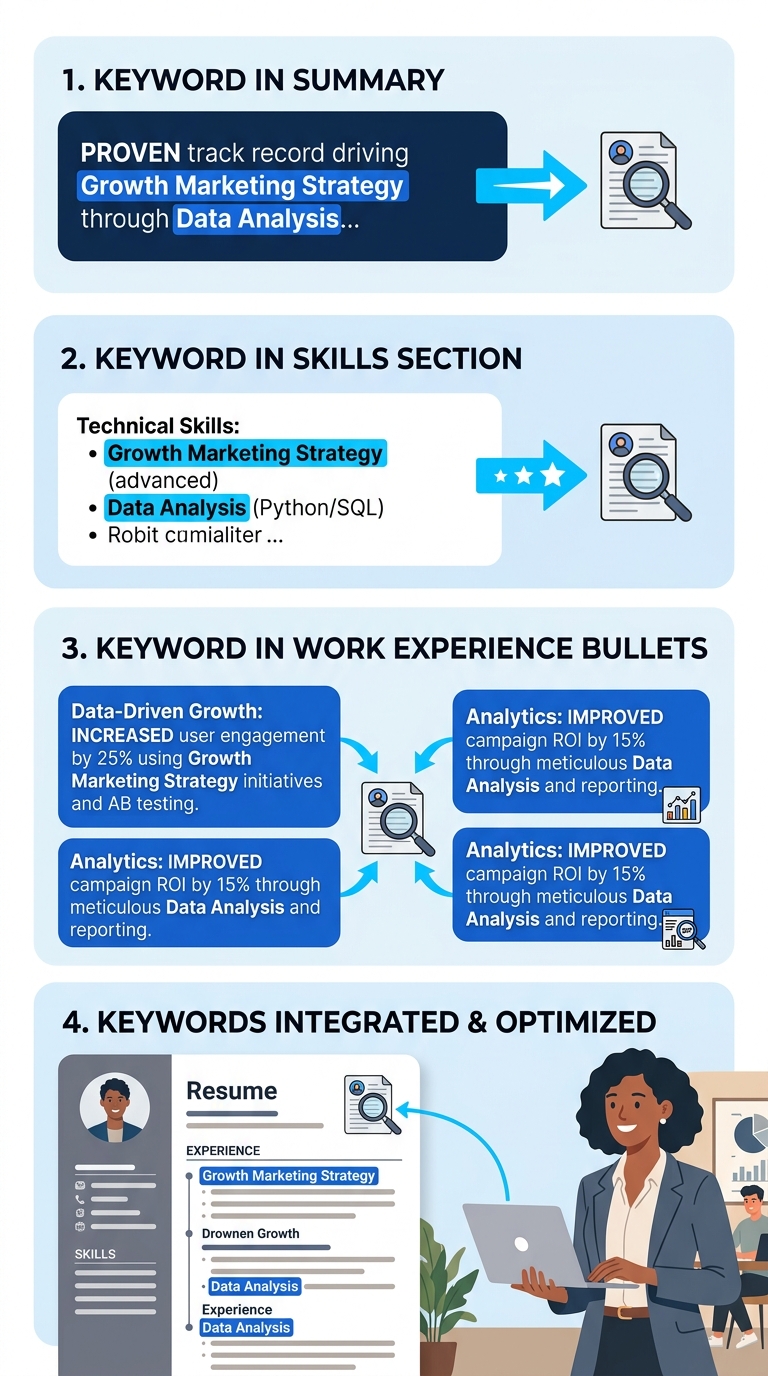
The 15-to-25 Keyword Window and Where Each One Goes
According to the 2026 ATS Resume Keywords Guide from Uppl.ai, the optimal range is 15-25 relevant keywords per resume. Fewer than 15 and the parser may not accumulate enough relevance signals. More than 25 and you risk triggering keyword stuffing detection, especially when the same terms cluster in a single section.
Distribution matters as much as count. Skills-first formatting—placing a dedicated skills section immediately after your summary—front-loads high-density keywords where ATS platforms weight them most heavily. But those same keywords need to reappear contextually in your work experience bullets, where they carry more weight for both semantic scoring and human credibility.
A practical breakdown for a 2-page resume targeting a product management role:
| Resume Section | Keyword Count | Purpose |
|---|---|---|
| Summary/Value Proposition | 3-5 | Signal core identity and seniority level |
| Skills Section | 8-12 | High-density cluster for ATS initial scan |
| Work Experience Bullets | 10-15 | Contextual proof that skills were applied |
| Education/Certifications | 2-4 | Domain-specific credentials and tools |
Notice the overlap: your skills section might list “Agile methodology” while a bullet under your most recent role says “facilitated bi-weekly sprint retrospectives for a 12-person engineering team, reducing cycle time 18%.” The keyword appears in two places, in two different forms, giving the parser two data points and giving the recruiter a concrete example.
Writing Contextual Bullet Points That Score and Read Well
The X-Y-Z impact formula—Accomplished [X] as measured by [Y], by doing [Z]—has become the standard structure for contextual job descriptions that work for both audiences. Modern ATS parsers prioritize quantified metrics and specific outcomes over generic responsibilities, and recruiters scanning resumes in 6-8 seconds look for numbers as visual anchors.
Consider the difference:
- Generic: “Managed a team and improved processes.”
- Contextual: “Managed a 9-person operations team through a warehouse management system migration, reducing order fulfillment errors 27% and cutting average processing time from 4.2 to 2.8 days.”
The second bullet contains at least 6 semantic keywords (operations, warehouse management, migration, order fulfillment, processing time, team management) while reading as a genuine accomplishment rather than a keyword list. This is the balance described in a May 2026 analysis on Medium: “The strongest resumes balance two goals simultaneously… That balance is difficult. And increasingly valuable. Because modern hiring pipelines are hybrid systems.”
The goal of semantic resume writing is to make every bullet point do double duty: score with the parser AND convince the human that you’ve actually done the work.
We’ve written extensively about how resume optimization needs to serve both the ATS and the human reader, and the principle holds even as the underlying technology evolves. The parser gets smarter, but the recruiter’s 6-8 second scan window hasn’t expanded.
Resume Authenticity Under Algorithmic Pressure
Here’s where many candidates stumble. The pressure to optimize for ATS scoring creates a temptation to inflate, fabricate, or adopt language that doesn’t represent real experience. A resume that perfectly mirrors a job posting but describes work you didn’t do will clear the ATS hurdle and then collapse in the interview, or worse, during background verification.
Resume authenticity serves a practical function beyond ethics. Human recruiters bring contextual understanding that algorithms lack: they read for cultural fit, career trajectory coherence, and whether your described accomplishments match the seniority of your titles. According to iCreatives’ analysis of skill-matching algorithms, “Human recruiters bring a deep understanding of the organization’s culture, values, and specific job requirements. They can consider the broader context and nuances of a role beyond what is captured in a job description or candidate profile.”
This means your semantic mirroring needs to stay rooted in real experience. If you’ve never worked with Kubernetes, don’t embed it in a bullet point just because the posting mentions it. Instead, identify the genuine overlaps between your background and the role’s requirements. If you used Docker in a development environment, say so honestly. The semantic parser will map Docker’s relationship to container orchestration. And a recruiter reading your resume can follow up on Docker experience in an interview without discovering a fabrication.
For candidates dealing with gaps or career pivots, framing strategies that work on hiring managers become especially important. Authentic framing of unconventional experience often scores better than forced keyword insertion, because the contextual sentences you write around real experience generate richer semantic signals than isolated terms dropped into a skills list.
Format Decisions That Affect Parsing
ATS-safe formatting remains a prerequisite, even though the fears about it are sometimes overblown. The r/resumes community on Reddit makes a fair point: “Make your resume look good enough that a human would want to read it. Modern systems understand context. If a company’s ATS chokes on a simple table in 2025, you’re probably dodging a bullet anyway.”
That said, certain formatting choices still trip up parsers reliably. Enhancv’s testing across major ATS platforms confirms that both .docx and text-based PDFs parse successfully in most systems. Single-column layouts with standard section headers (“Work Experience,” “Education,” “Skills”) give parsers the clearest structural signals. The resources at ResumeWriting.net cover specific layout patterns worth auditing, and our ATS format audit guide walks through the most common failure points.
A useful rule of thumb: keep the format clean enough that a 2015-era ATS could parse it, while writing the content sophisticated enough for a 2026 semantic parser to score it. Clean structure is the floor. Contextual, metric-rich writing is the ceiling.
Warning: Avoid two-column layouts, text boxes, headers/footers for contact information, and embedded images or icons. These elements cause roughly 75% of parsing failures, according to ATS formatting guidance from multiple industry sources.
What Still Isn’t Settled
The shift toward semantic hiring systems raises questions the industry hasn’t resolved. Skill graphing, experience mapping, and capability inference are all active areas of development, and different ATS vendors implement them at different levels of sophistication. A resume optimized for Workday’s parser may score differently in Greenhouse or iCIMS, and candidates rarely know which system a company uses before they apply.
There’s also an open question about how far semantic inference will go. Current LLM-based screening frameworks, like the multi-agent system described in a 2025 paper from arXiv, can “analyze job relevance and infer contextual qualifications dynamically.” If these models become standard in ATS platforms, the gap between what you wrote and what the system understands you meant will keep narrowing. That could be good news for strong candidates with unconventional backgrounds. It could also mean that resume authenticity becomes easier to verify algorithmically, making inflated claims riskier than they already are.
For now, the 15-25 keyword range, semantic mirroring technique, and X-Y-Z bullet structure represent the most reliable strategy for writing a resume that clears both the algorithmic and human filters. The technology will keep evolving, but the underlying principle is stable: write specific, honest, contextual descriptions of real work, and both the parser and the recruiter will find what they’re looking for.