
Code For Good Now handed survey respondents two AI-generated resumes this week. The qualifications matched. The formatting matched. The bullet points were copied word-for-word. The only variable was the name printed at the top: Emily on one, James on the other. James received a 97% approval rating. Emily’s resume was flagged as “weak,” and respondents openly questioned whether she possessed the skills she claimed. The researcher behind the study, Chatoo, summarized the double standard in a line that’s been circulating across LinkedIn and hiring forums since: “When men use AI, we question their effort. When women use AI, we question their integrity.”
That finding, reported by Fortune on May 10, lands at a moment when candidates increasingly rely on AI-powered resume builders and optimization tools to compete. The uncomfortable truth is that the same large language models powering those tools exhibit measurable gender discrimination in hiring algorithms during controlled experiments. And the humans on the receiving end appear to layer their own biases on top, creating a compounding problem that neither technology nor good intentions have solved.

The Data Behind the Double Standard
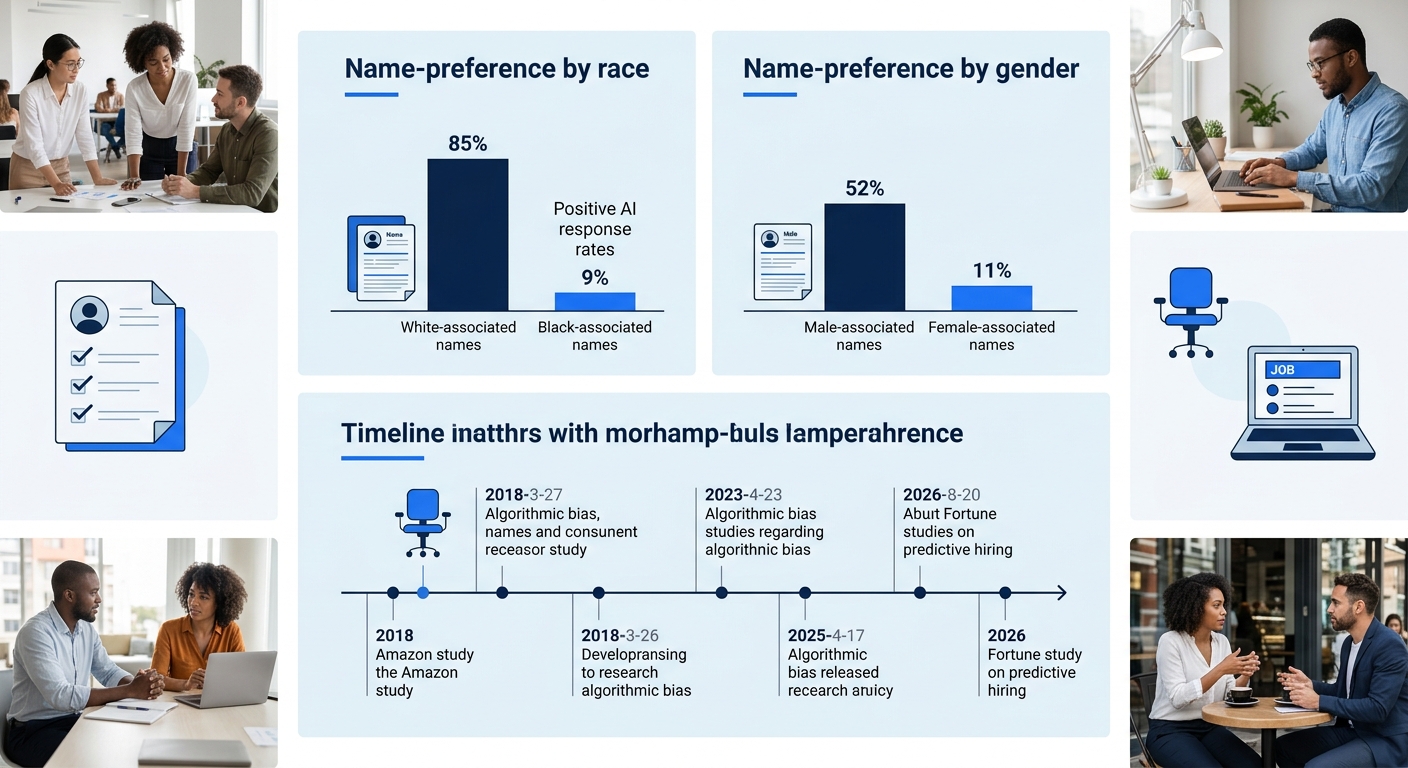
The Emily-and-James experiment would be alarming enough on its own. But it fits into a growing body of research that documents algorithmic hiring bias at a scale most job seekers don’t realize. A University of Washington study published in October 2024 tested three large language models from Mistral AI, Salesforce, and Contextual AI on resume ranking tasks. The models favored white-associated names 85% of the time. They preferred male-associated names 52% of the time versus female-associated names just 11% of the time. And the intersectional results were worse still: Black male-associated names were never ranked above white male names in any of the tested configurations. The researchers noted that outside of a New York City audit law, no regulatory framework requires independent testing of these systems before employers deploy them.
A separate Stanford study from October 2025 found that when ChatGPT generated resumes based on identical input data, it portrayed women as younger and less experienced while giving older men the highest competency ratings. These aren’t fringe models running on outdated training data. These are the engines behind popular resume builders and ATS scoring tools that millions of candidates interact with every week. The question of resume builder fairness is no longer theoretical. The evidence says the tools themselves carry inherited assumptions about whose experience sounds credible.
The Amazon precedent remains instructive here. Back in 2018, Amazon scrapped an internal AI hiring tool after discovering it systematically downgraded resumes containing words like “women’s” (as in “women’s chess club captain”) and preferred language patterns more commonly found in male applicants’ submissions, like “executed” and “captured.” The tool had been trained on a decade of resumes submitted to the company, which skewed heavily male in technical roles. The training data encoded the hiring patterns of the past, and the algorithm learned to replicate them. Amazon caught the problem internally and shut it down. Most companies using third-party AI screening tools don’t have visibility into what their models learned or from whom.
Why “Neutral” Algorithms Keep Producing Biased Results
The instinct when confronting these numbers is to assume the fix is straightforward: strip out names, remove gender signals, let the algorithm evaluate pure content. Several AI resume bias detection tools already offer this kind of blinding, masking names, pronouns, and graduation years before scoring. But Brookings researchers have documented a subtler problem that survives even aggressive anonymization. Algorithms classify information based on proxy variables, patterns in word choice, sentence structure, and career trajectory that correlate with gender or race without explicitly naming them. A resume that describes “collaborative facilitation of cross-functional teams” triggers different scoring weights than one describing “aggressive revenue capture across enterprise accounts,” and those language patterns track with gendered communication norms in ways the model never needs to be told about.
This is the core challenge with resume optimization ethics in 2026. When candidates use AI tools to rewrite their bullets, those tools often nudge language toward patterns that score well with ATS systems. But “scoring well” means matching the patterns that existing successful hires exhibited, and if those historical hires skewed male in a given industry, the optimization itself becomes a vector for bias. We’ve explored how AI-polished resume content can obscure a candidate’s authentic story in previous coverage, and gender bias adds another dimension to that risk. The tool doesn’t need to know your gender to produce gendered outputs. It only needs your input to trigger different statistical pathways through its training data.
The tool doesn’t need to know your gender to produce gendered outputs. It only needs your input to trigger different statistical pathways through its training data.
A follow-up University of Washington study from November 2025 added an even more troubling layer: when AI systems made biased recommendations to human reviewers, those reviewers followed the biased recommendations 90% of the time in severe-bias scenarios. The algorithm doesn’t operate in a vacuum. It feeds a recommendation to a recruiter who already has seven seconds of attention to give your resume. If the system ranks your application lower, the human reviewer almost never overrides that ranking. The ongoing tension between human judgment and algorithmic screening keeps getting resolved in the algorithm’s favor, regardless of whether the algorithm earned that trust.
Practical Defenses for Candidates Navigating Biased Systems
Knowing that bias exists in these systems doesn’t help much if you still need to get hired. Here’s where things get concrete. The first and most actionable step is to run your resume through multiple AI scoring tools rather than trusting a single one. Different platforms use different underlying models, and comparing scores across three or four tools can surface discrepancies that hint at model-specific biases. If one tool rates your resume significantly lower than the others with no clear explanation tied to keywords or formatting, that’s a signal worth investigating. The landscape of free and paid resume builders varies widely in the models they use, and diversifying your testing gives you a broader read on how algorithms perceive your document.
Second, audit your own language for unintentional gender coding. Research on gendered word patterns in professional writing is well-established: words like “nurturing,” “supportive,” and “collaborative” register differently than “driven,” “executed,” and “captured” in models trained on historically male-dominated hiring data. This doesn’t mean you should strip your resume of collaborative language if that accurately describes your work. It means you should pair relational descriptions with outcome-specific language. Instead of “Supported cross-functional team alignment,” try “Coordinated a 12-person cross-functional team that shipped the Q3 product release two weeks ahead of schedule.” The specificity displaces the gendered signal. We’ve covered why vague accomplishments underperform measurable ones in ATS parsing, and the gender-bias angle reinforces that same principle from a different direction.
Third, consider the name and header section of your resume carefully. The viral debate over whether changing a name on a resume changes callback rates keeps resurfacing because the underlying data keeps confirming the pattern. If you have a name that signals gender or ethnicity, you face a statistical disadvantage in systems that haven’t been audited for bias. Some candidates use initials or professional names as a practical workaround. That choice is personal, and nobody should have to obscure their identity to get a fair reading. But knowing the data lets you make an informed decision about how much identifying information to include in the header versus in a later-stage conversation.
Fourth, pay attention to which companies disclose their screening practices. New York City’s Local Law 144 requires employers using automated employment decision tools to conduct annual bias audits and publish the results. California’s 2024 recognition of intersectionality as a protected attribute creates additional legal ground for candidates who believe combined identity factors influenced an algorithmic decision. Companies that proactively mention bias auditing in their hiring process descriptions are, at minimum, aware of the problem. Companies that say nothing about how they screen are a black box, and your resume enters that black box with whatever biases the model carries.

What the Evidence Still Can’t Tell Us
The research published in the last eighteen months gives us something we didn’t have before: specific numbers attached to specific models producing specific biased outcomes. The University of Washington studies, the Stanford findings on gendered age bias, and the Code For Good Now experiment all point in the same direction. Algorithmic hiring bias is measurable, reproducible, and widespread across the major LLM architectures that power hiring tools.
What the evidence can’t yet tell us is how much of the bias that reaches a real candidate originates from the AI screening layer versus the human evaluation layer versus the resume optimization layer. The Fortune study on Emily and James tested human respondents reacting to AI-generated resumes, and the 97%-versus-“weak” split happened entirely in the human judgment. The UW studies tested LLMs directly. The Stanford study tested generative AI output. Each experiment isolates a different link in the chain, and the cumulative effect on an actual job seeker who uses an AI builder to write a resume, submits it through an AI screener, and then gets evaluated by a human influenced by the AI’s ranking involves all three layers compounding simultaneously. Nobody has measured that full pipeline end-to-end with controlled variables for gender discrimination in hiring algorithms, partly because every employer’s pipeline is proprietary and different.
Warning: No single bias audit covers the full hiring pipeline. A resume builder might be fair while the ATS screener introduces bias, or vice versa. Candidates should assume that bias can enter at any stage and take protective measures at each one.
The regulatory landscape remains fragmented. One city has an audit law. One state recognizes intersectionality. Federal legislation on AI resume bias detection in employment decisions doesn’t exist yet. The gap between what researchers can demonstrate in controlled settings and what candidates experience in the wild stays wide, and it stays wide because the companies building these tools have limited incentive to publish their own audit results when no law compels them to. The uncomfortable reality for job seekers is that protecting yourself from biased AI tools currently requires you to do work that the tools’ developers should be doing: testing, comparing, questioning, and compensating for systems that were built without adequate safeguards. That burden falls disproportionately on the people the bias harms most, and no amount of individual resume optimization resolves a structural failure in how hiring technology gets built and deployed.