
Workday’s Illuminate platform, Greenhouse, and iCIMS all shipped large language model integrations into their applicant tracking systems between late 2023 and mid-2024. The upgrade sounded like progress: instead of matching keywords one-to-one against job descriptions, these systems would understand what a resume actually said. Semantic matching. Context-aware skills extraction. Experience parsing that could infer competency from narrative descriptions.
The promise was better candidates surfacing faster. What actually happened over the following two years was stranger and more damaging than anyone in talent acquisition predicted.
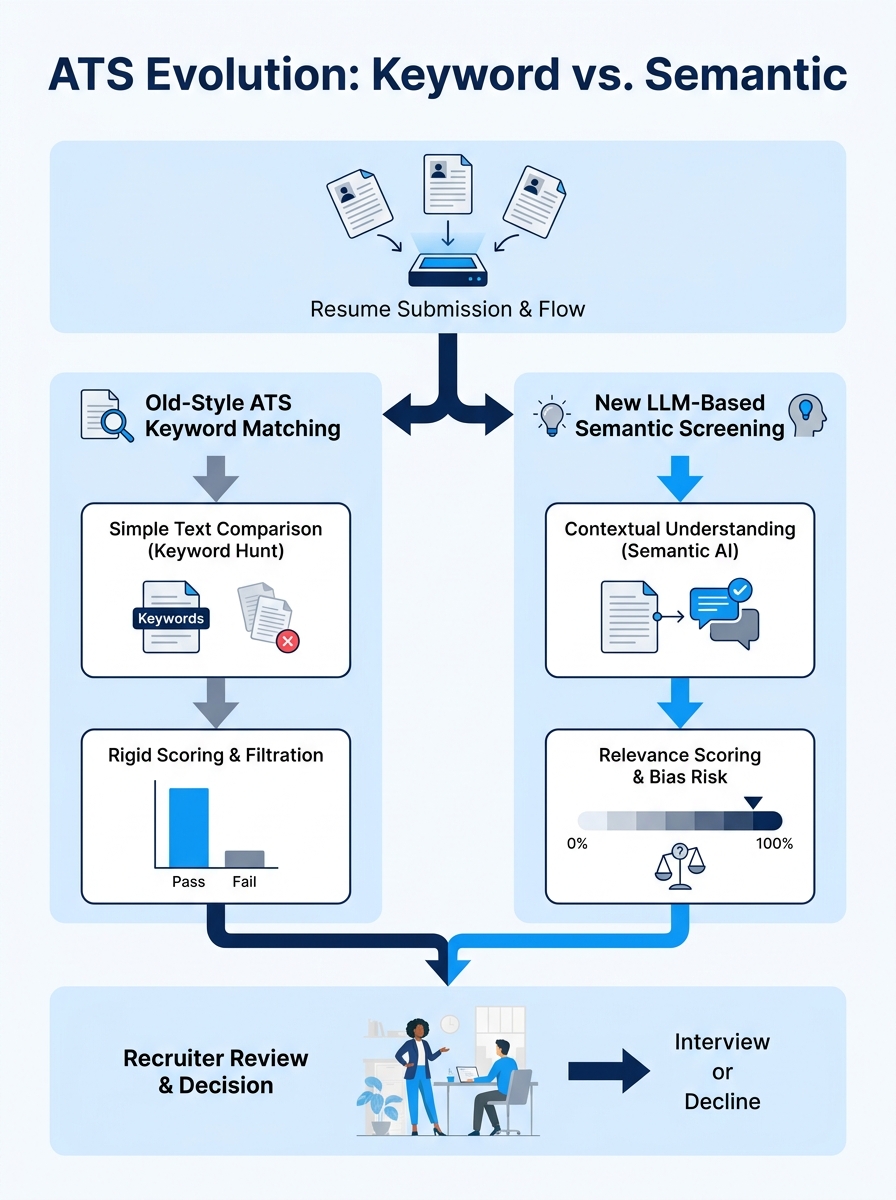
When Keyword Matching Gave Way to Semantic Screening
For roughly two decades, resume algorithm optimization meant one thing: mirror the language in the job posting. If the listing said “project management,” you wrote “project management.” If it said “Agile methodology,” you included “Agile methodology.” The system ran a text comparison, spat out a match score, and recruiters saw whoever cleared the threshold.
That era ended when major ATS platforms began deploying LLM-based screening. The new models didn’t need exact keyword matches. They could determine that “led cross-functional sprints” probably meant Agile experience, and that “managed P&L for a $12M division” signaled financial acumen even without the phrase “financial management” appearing anywhere.
This should have been good news for candidates. Rigid keyword-stuffing strategies were supposed to become irrelevant. And for a brief window, roughly six to eight months, the playing field did feel more open. Qualified candidates who wrote naturally about their experience started getting through filters they’d previously been blocked by.
But the training data underneath these models carried problems that wouldn’t surface until researchers started looking.
The Bias Findings Landed Hard
In October 2024, researchers at the University of Washington published a study showing that AI tools exhibit measurable biases when ranking job applicants’ names by perceived race and gender. The findings were specific and difficult to dismiss: screening tools favored white-associated names 85% of the time, and male names were preferred over female names at rates between 52% and 85%.
These weren’t obscure, experimental models. Companies had already begun deploying the latest LLMs to write job descriptions, sift through resumes, and screen applicants at scale.
The pattern of algorithmic hiring discrimination didn’t come from nowhere. As research published in Humanities and Social Sciences Communications documented, algorithmic bias in recruitment stems from limited training datasets and the unconscious assumptions of the people who build the systems. The algorithms learned from historical hiring data, and that data reflected decades of human preference patterns.
Forbes reported in January 2026 that AI hiring systems often “inherit or exacerbate human biases embedded in their training data” because models trained on old resumes repeat past patterns rather than question them. By the time most employers recognized the scale of the problem, millions of applications had already been processed through biased pipelines.
The human vs machine resume reading gap widened here. A trained recruiter reviewing a resume might catch their own biases, correct for them, or at least be held accountable. An algorithm processing 10,000 applications per day had no such self-awareness, and the AI hiring bias operated invisibly at a volume no human review process could match.
We’ve covered how the AI resume bias paradox affects job seekers in detail, and the evidence has only gotten more stark since that piece was published.
Then Came the Application Flood
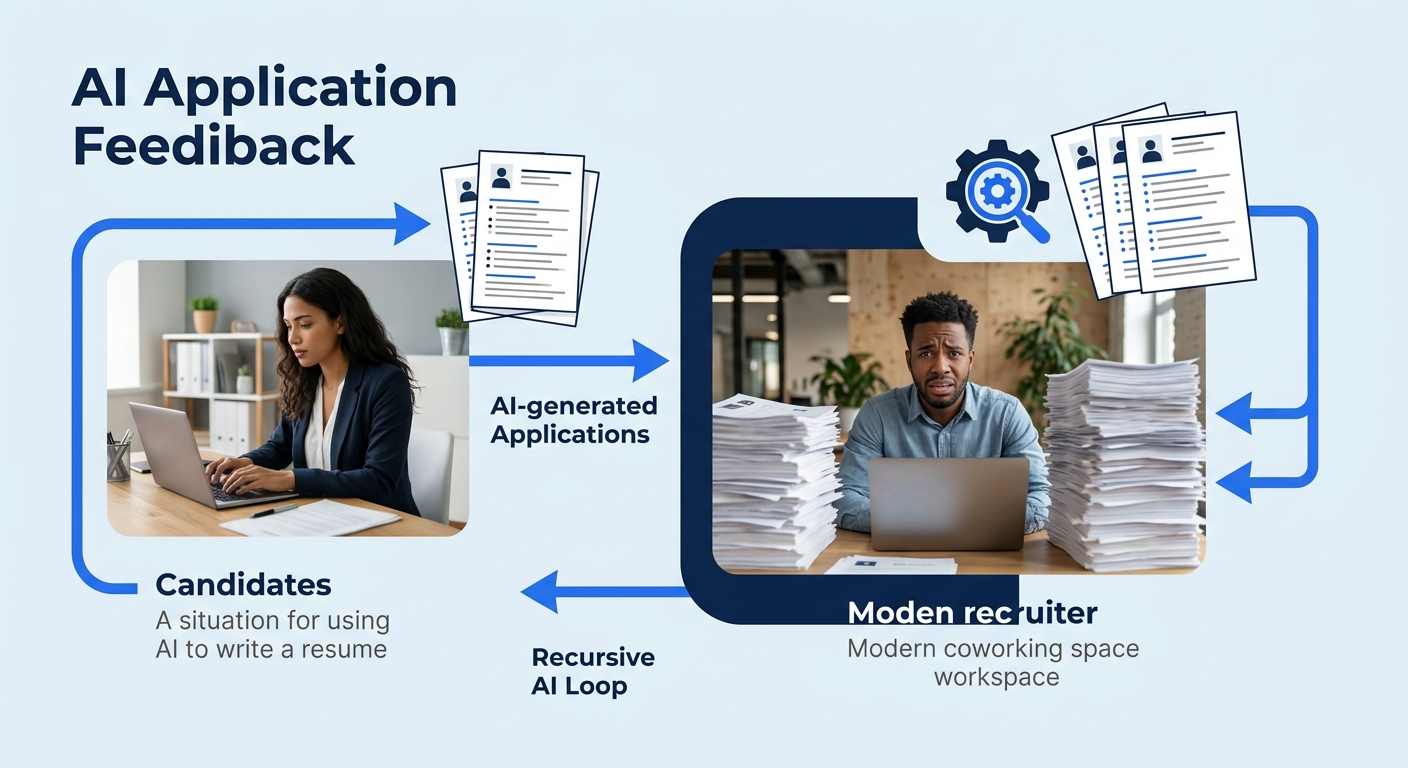
While the bias research accumulated, a parallel disruption was building on the candidate side. By early 2025, ChatGPT, Claude, Gemini, and dozens of specialized resume tools had made it trivially easy to generate polished applications. The numbers were staggering: 78% of all job submissions were AI-generated or AI-assisted.
For recruiting teams, the math broke. A single job posting that used to attract 200 applications now pulled 800 or more. The screening systems designed to save time were now drowning in volume, and the AI-generated resumes were specifically optimized to score well on AI screening tools.
This created an absurd feedback loop. Candidates used AI to write resumes designed to pass AI filters. Employers used AI to screen those AI-generated resumes. And somewhere in the middle, the actual question of whether a person could do the job got lost.
62% of hiring managers say AI-generated resumes without personalization are more likely to be rejected, and 78% say personalized details signal genuine interest and fit.
Recruiters started noticing patterns. AI-generated resumes shared a flatness, a generic quality that was technically correct but personally vacant. As one resume-writing professional noted, “AI can make writing a resume easier, but it can’t replace genuine thought about what makes your experience distinct.” A well-crafted human-written resume allows candidates to express personality, passion, and cultural fit in ways AI tools genuinely struggle to replicate.
The rejection rates reflected this. Resume Now’s 2025 report found that 62% of hiring managers said AI-generated resumes without personalization were more likely to be rejected. If your resume reads like it could belong to any of the 400 other applicants in the pile, that’s a problem regardless of how well it scores on keyword match.
This flood is part of why recruiters now spend an average of 11.2 seconds per resume, down from already-low figures in previous years. Volume increased. Time per application decreased. And the gap between what the algorithm selects and what a human would choose grew wider.
Detection Tools Made Everything Messier
Employers responded to the flood with a predictable move: AI detection tools. By early 2026, roughly 14% of employers had implemented systems to flag AI-generated content in applications.
The detection tools carried their own bias problems. Non-native English speakers were flagged at a 23% false positive rate, compared to 4% for native speakers. PhD and MBA graduates were flagged at nearly double the rate of other applicants because their formal, structured writing style resembled AI output.
Think about what that means in practice. A qualified engineer from Brazil, writing carefully in their second language, gets flagged as “probably AI-generated.” A Harvard MBA whose writing is naturally precise and structured gets the same flag. The tool designed to ensure authenticity ends up penalizing people for writing well or writing differently.
And the formatting constraints kept compounding. ATS systems still can’t reliably parse all file formats. Headers, footers, templates, borders, lines, and symbols can all cause parsing failures. Functional resumes without dates don’t score well with newer systems. Your resume needs to be readable by software that varies wildly from company to company while also being compelling enough for the human who sees it after.
If you’ve been struggling with why well-written bullet points still fail ATS systems, this dual-audience problem is usually the root cause.
A Different Resume Started to Win
Somewhere in the chaos of 2025 and into 2026, a distinct resume archetype began emerging from the candidates who actually got hired. It looked different from both the old keyword-stuffed format and the AI-polished generic template.
The 2026 resume trends point toward documents that are evidence-based, specific to the point of being verifiable, and structured for both algorithmic parsing and human engagement. Here’s what changed in practice:
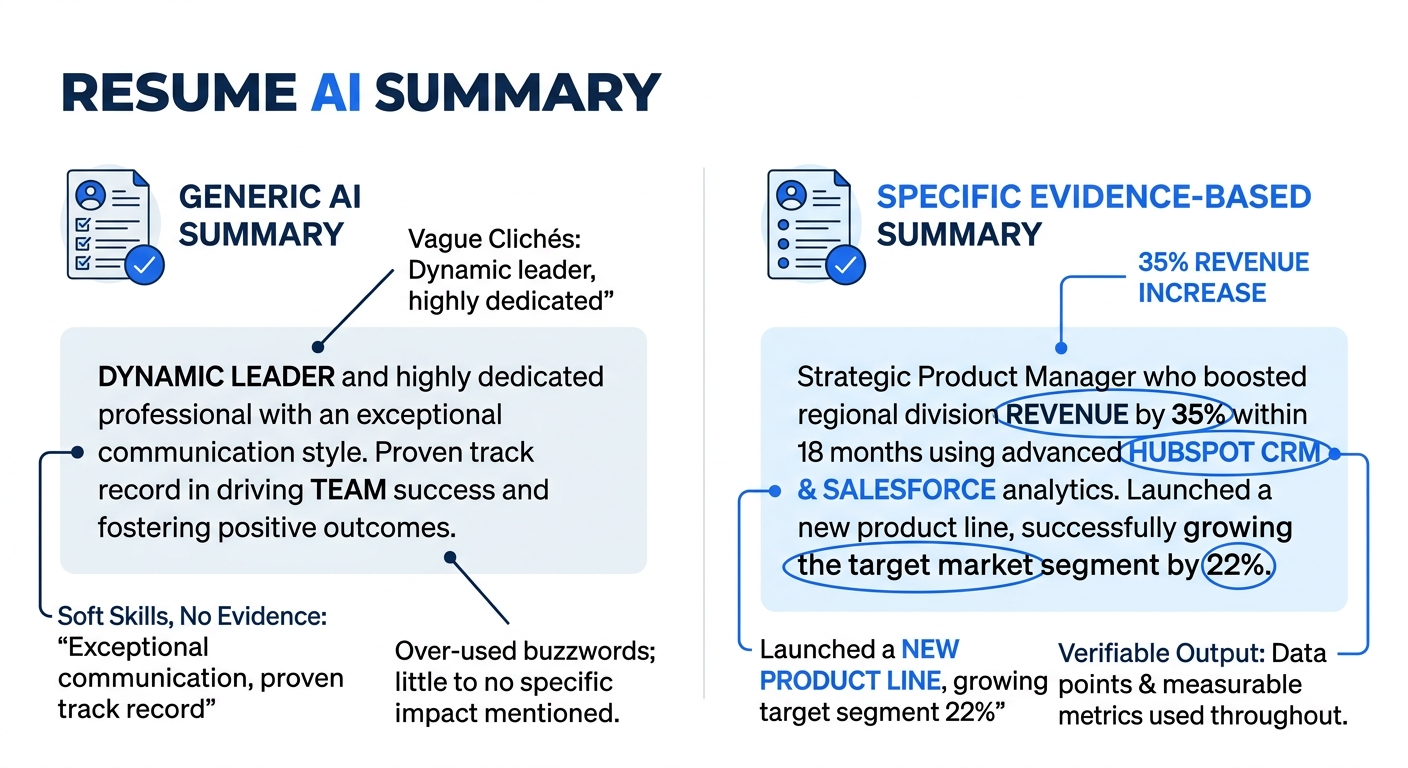
Value proposition summaries replaced objective statements. Instead of “Seeking a challenging role in data analytics,” the winning resumes opened with something like “Reduced customer churn by 14% over two quarters by rebuilding the retention scoring model in Python and Snowflake.” Specific tools, specific outcomes, specific timeframes.
Impact metrics followed the X-Y-Z format consistently. “Accomplished [X] as measured by [Y] by doing [Z].” This structure satisfies the algorithm’s need for parseable achievement data while giving a human reader the concrete story they need to evaluate competence.
Formatting stayed deliberately simple. No headers or footers containing critical information. No tables, text boxes, or complex layouts. Standard section headings (Experience, Education, Skills) that any ATS can parse without choking. As Columbia’s career education team advises, candidates should complete all fields in online applications, even optional ones, and customize each resume for the specific position.
Keywords were woven into accomplishment statements rather than listed separately. The old approach of dumping a “Skills” section full of buzzwords at the bottom still works for basic ATS matching, but semantic screening systems now evaluate how keywords appear in context. Saying you “managed Kubernetes clusters supporting 2,000 daily deployments” carries more weight than listing “Kubernetes” in a skills table.
The approach to matching job descriptions without falling into generic language has become the central skill of resume writing in 2026.
Tip: When tailoring your resume for both algorithms and humans, write your accomplishments first in natural language with specific numbers. Then check whether the key terms from the job posting appear organically in those statements. If they don’t, rework the phrasing to include them within the context of real achievements. Pasting keywords into a separate list no longer gets you through semantic screening.
Where the Data Looks Today
The screening landscape of 2026 has settled into an uneasy equilibrium. AI hiring bias hasn’t been solved. It’s been partially contained through regulation (New York City’s Local Law 144 requires annual bias audits for automated hiring tools) and partially managed through hybrid screening models that keep humans involved at critical decision points.
The most effective approach documented so far works in tiers: the top 15-20% of resumes get auto-advanced to phone screens, the bottom 50-60% are auto-rejected, and the middle 20-35% go to human reviewers who catch false negatives. That middle band is where resume algorithm optimization matters most, because you’re competing against the algorithm’s uncertainty about you.
And 79% of hiring leaders still insist that final decisions must be human-led. The technology screens at volume. The human decides.
For you as a job seeker, the practical reality is that your resume needs to satisfy two audiences with different reading methods and different priorities. The algorithm wants parseable structure, contextual keywords, and clean formatting. The human wants to see a real person with specific experience, distinct accomplishments, and enough personality to suggest cultural fit.
The candidates getting hired in 2026 are the ones who’ve figured out that these two goals don’t actually conflict. A resume built around genuine, specific, measurable accomplishments, formatted cleanly and titled with standard section headings, reads well to both audiences. The problem was never that algorithms and humans want fundamentally different things. The problem was that the shortcuts people used to game algorithms (keyword stuffing, generic phrasing, AI-generated boilerplate) happened to be the exact things that make human readers lose interest.
The new resume archetype isn’t a trick or a template. It’s a document that treats specificity as its primary virtue, presents evidence rather than claims, and trusts that a well-told professional story will score well on any system designed to find competent people. That’s a harder resume to write than the old keyword-matched version or the AI-generated alternative. It’s also the one that’s working.